Intel Core i9-14900KS Review: The Swan Song of Raptor Lake With A Super Fast 6.2 GHz Turbo
Published: May 10nd 2024 10:30am on AnandTech
For numerous generations of their desktop processor releases, Intel has made available a selection of high-performance special edition "KS" CPUs that add a little extra compared to their flagship chip. With a lot of interest, primarily from the enthusiasts looking for the fastest processors, Intel's latest Core i9-14900KS represents a super-fast addition to its 14th Generation Core lineup with out-of-the-box turbo clock speeds of up to 6.2 GHz and represents the last processor to end an era as Intel is removing the 'i' from its legendary nomenclature for future desktop chip releases.
Reaching speeds of up to 6.2 GHz, this sets up the Core i9-14900KS as the fastest desktop CPU in the world right now, at least in terms of frequencies out of the box. Building on their 'regular' flagship chip, the Core i9-14900, the Core i9-14900KS is also using their refreshed Raptor Lake (RPL-R) 8P+16E core chip design with a 200 MHz higher boost clock speed and also has a 100 MHz bump on P-Core base frequency.
This new KS series SKU shows Intel's drive to offer an even faster alternative to their desktop regular K series offerings, and with the Core i9-14900KS, they look to provide the best silicon from their Raptor Lake Refresh series with more performance available to unlock to those who can. The caveat is that achieving these ridiculously fast clock speeds of 6.2 GHz on the P-Core comes at the cost of power and heat; keeping a processor pulling upwards of 350 W is a challenge in its own right, and users need to factor this in if even contemplating a KS series SKU.
In our previous KS series review, the Core i9-13900KS reached 360 W at its peak, considerably more than the Core i9-13900K. The Core i9-14900KS, built on the same core architecture, is expected to surpass that even further than the Core i9-14900K. We aim to compare Intel's final Core i series processor to the best of what both Intel and AMD have available, and it will be interesting to see how much performance can be extrapolated from the KS compared to the regular K series SKU.
AMD Hits Record High Share in x86 Desktops and Servers
Published: May 10nd 2024 7:00am on AnandTech

Coming out of the dark times that preceded the launch of AMD's Zen CPU architecture in 2017, to say that AMD has turned things around on the back of Zen would be an understatement. Ever since AMD launched its first Zen-based Ryzen and EPYC processors for client and server computers, it has been consistently gaining x86 market share, growing from a bit player to a respectable rival to Intel (and all at Intel's expense).
The first quarter of this year was no exception, according to Mercury Research, as the company achieved record high unit shares on x86 desktop and x86 server CPU markets due to success of its Ryzen 8000-series client products and 4th Generation EPYC processors.
"Mercury noted in their first quarter report that AMD gained significant server and client revenue share driven by growing demand for 4th Gen EPYC and Ryzen 8000 series processors," a statement by AMD reads.
Desktop PCs: AMD Achieves Highest Share in More Than a Decade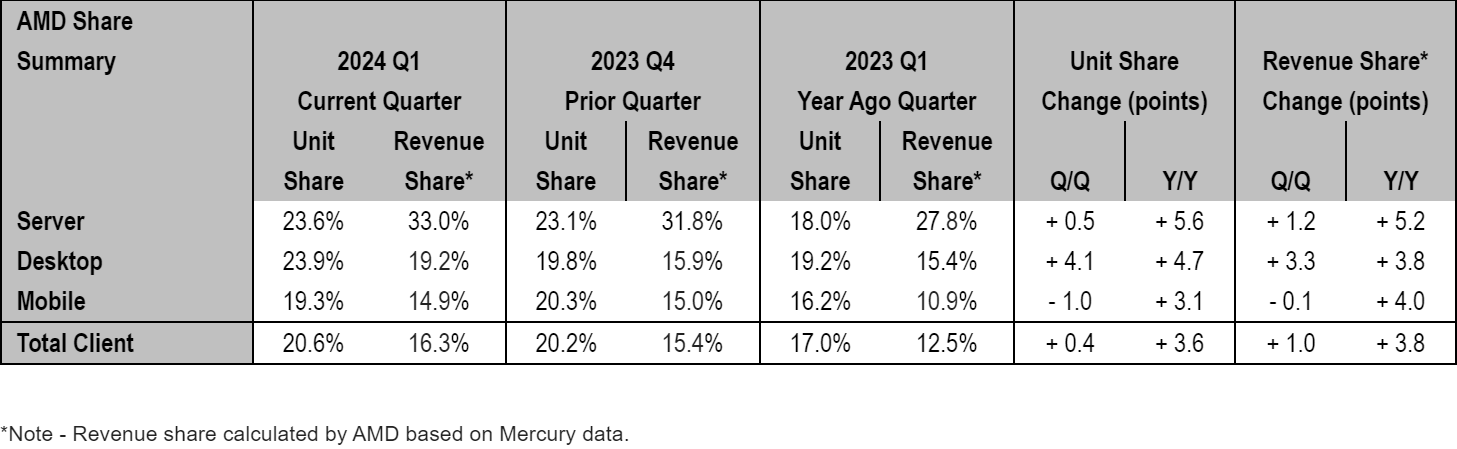
Desktops, particularly DIY desktops, have always been AMD's strongest market. After the company launched its Ryzen processors in 2017, it doubled its presence in desktops in just three years. But in the recent years the company had to prioritize production of more expensive CPUs for datacenters, which lead to some erosion of its desktop and mobile market shares.
As the company secrued more capacity at TSMC, it started to gradually increase production of desktop processors. In Q4 last year it introduced its Zen 4-based Ryzen 8000/Ryzen 8000 Pro processors for mainstream desktops, which appeared to be pretty popular with PC makers.
As a result of this and other factors, AMD increased unit sales of its desktop CPUs by 4.7% year-over-year in Q1 2024 and its market share achieved 23.9%, which is the highest desktop CPU market share the company commanded in over a decade. Interestingly, AMD does not attribute its success on the desktop front to any particular product or product family, which implies that there are multiple factors at play.
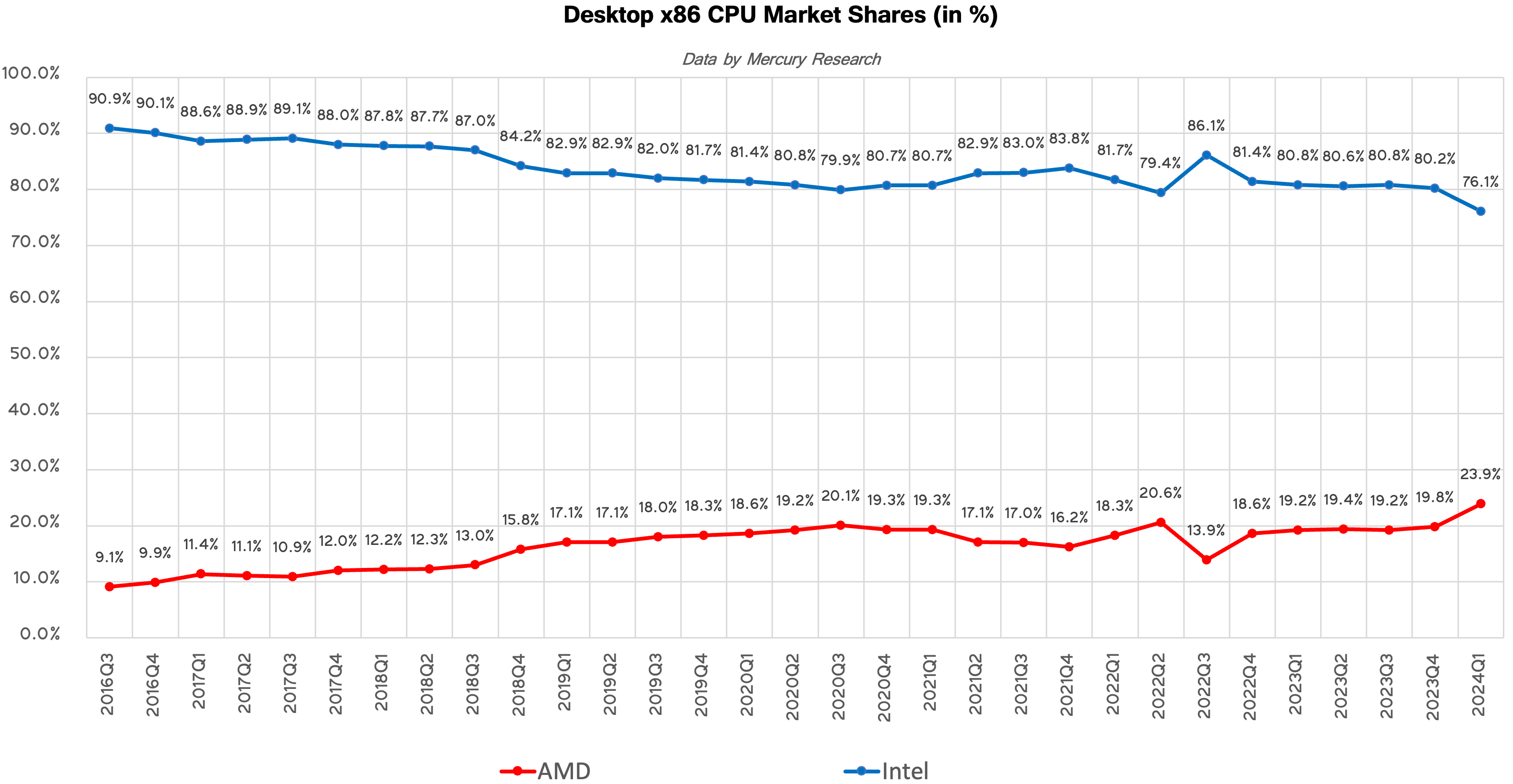
Mobile PCs: A Slight Drop for AMD amid Intel's Meteor Lake RampAMD has been gradually regaining its share inside laptops for about 1.5 years now and sales of its Zen 4-based Ryzen 7040-series processors were quite strong in Q3 2023 and Q4 2023, when the company's unit share increased to 19.5% and 20.3%, respectively, as AMD-based notebook platforms ramped up. By contrast, Intel's Core Ultra 'Meteor Lake' powered machines only began to hit retail shelves in Q4'23, which affected sales of its processors for laptops.
In the first quarter AMD's unit share on the market of CPUs for notebooks decreased to 19.3%, down 1% sequentially. Meanwhile, the company still demonstrated significant year-over-year unit share increase of 3.1% and revenue share increase of 4%, which signals rising average selling price of AMD's latest Ryzen processors for mobile PCs.
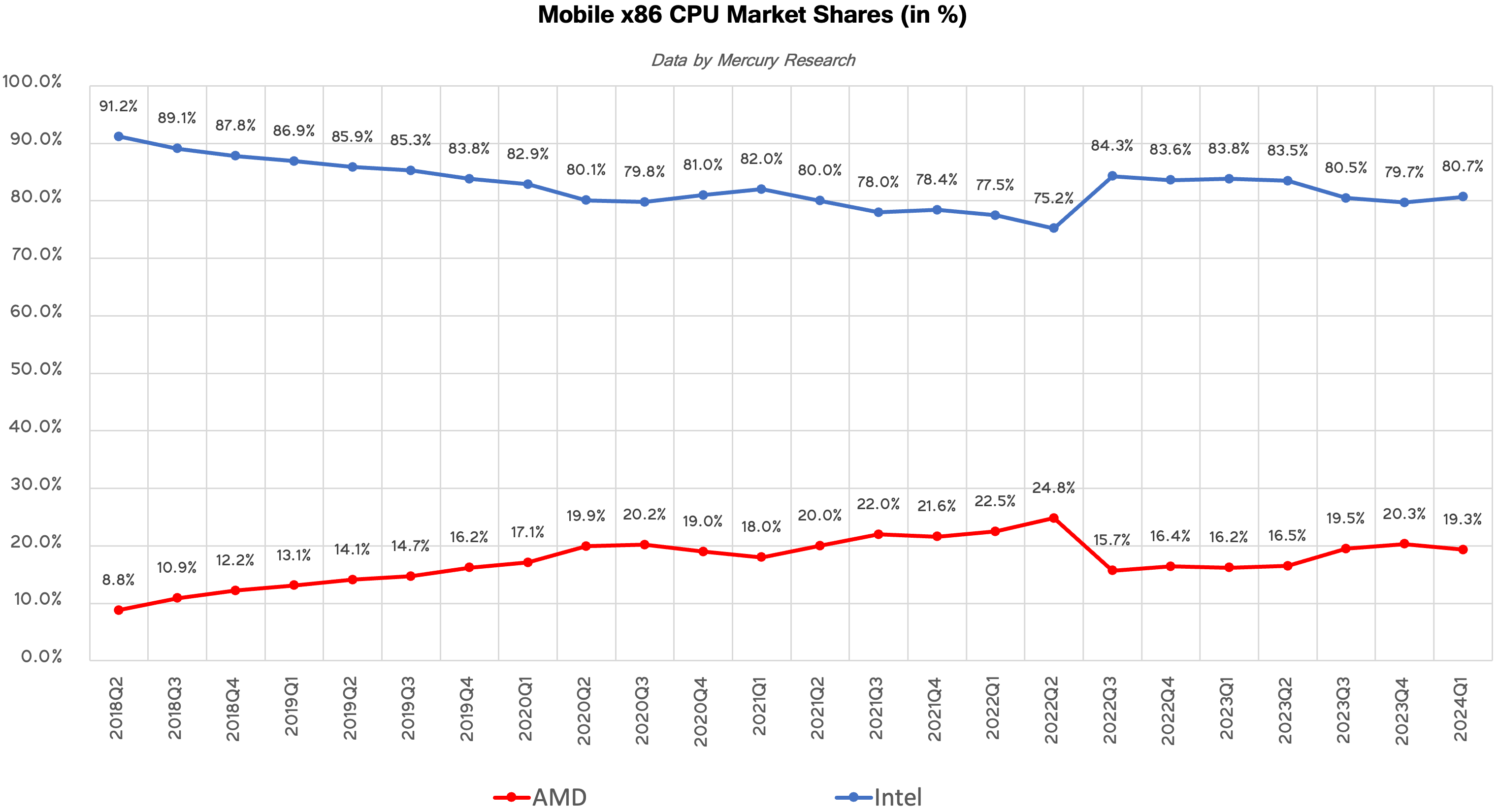
Client PCs: Slight Gain for AMD, Small Loss for IntelOverall, Intel remained the dominant force in client PC sales in the first quarter of 2024, with a 79.4% market share, leaving 20.6% for AMD. This is not particularly surprising given how strong and diverse Intel's client products lineup is. Even with continued success, it will take AMD years to grow sales by enough to completely flip the market.
But AMD actually gained a 0.3% unit share sequentially and a 3.6% unit share year-over year. Notably, however, AMD's revenue share of client PC market is significantly lower than its unit share (16.3% vs 20.6%), so the company is still somewhat pigeonholed into selling more budget and fewer premium processors overall. But the company still made a strong 3.8% gain since the first quarter 2023, when its revenue share was around 12.5% amid unit share of 17%.
Servers: AMD Grabs Another Piece of the MarketAMD's EPYC datacenter processors are undeniably the crown jewel of the company's CPU product lineup. While AMD's market share in desktops and laptops fluctuated in the recent years, the company has been steadily gaining presence in servers both in terms of units and in terms of revenue in the highly lucrative (and profitable) server market.
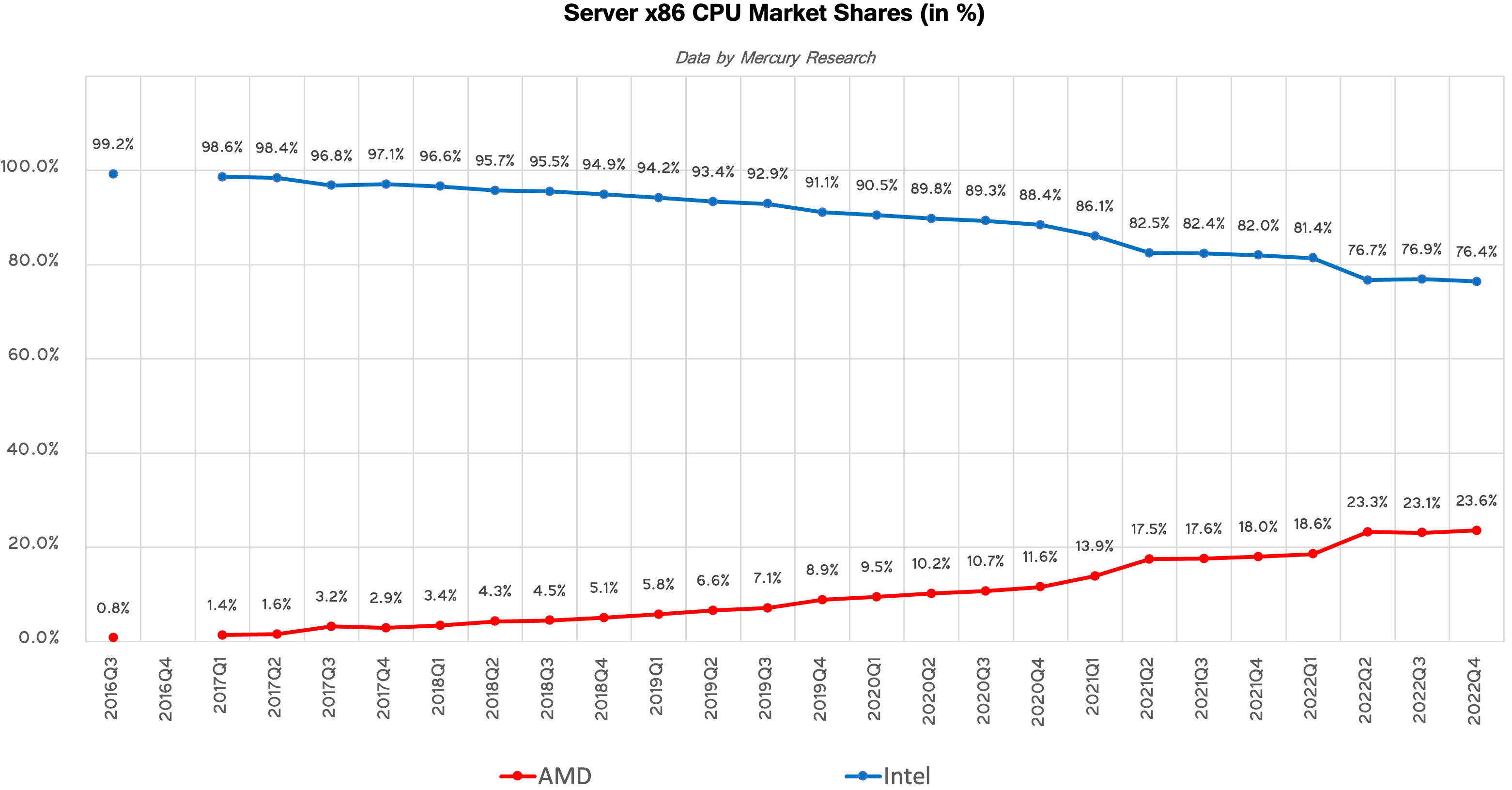
In Q1 2024, AMD's unit share on the market of CPUs for servers increased to 23.6%, a 0.5% gain sequentially and a massive 5% gain year-over-year driven by the ramp of platforms based on AMD's 4th Generation EPYC processors. With a 76.4% unit market share, Intel continues to dominate in servers, but it is evident that AMD is getting stronger.
AMD's revenue share of the x86 server market reached 33%, up 5.2% year-over-year and 1.2% from the previous quarter. This signals that the company is gaining traction in expensive machines with advanced CPUs. Keeping in mind that for now Intel does not have direct rivals for AMD's 96-core and 128-core processors, it is no wonder that AMD has done so well growing their share of the server market.
"As we noted during our first quarter earnings call, server CPU sales increased YoY driven by growth in enterprise adoption and expanded cloud deployments," AMD said in a statement.
Sabrent Launches Rocket Nano M.2-2242 SSD: Up to 5 GB/sec
Published: May 9nd 2024 8:00am on AnandTech

Sabrent tends to get into news when it launches ultra-high-performance SSDs for enthusiast-grade desktops, but this week the company introduced a completely different type of product: a small form-factor M.2-2242 SSD aimed at Lenovo's Legion Go handheld and ultra-thin laptops that don't accomodate M.2-2280 drives. And even though it's not an enthusiast-grade drive, the Rocket Nano still boasts with quite decent performance and capacity.
The Sabrent Rocket Nano 2242 (SB-2142) drive is based on the Phison E27T platform, a PCIe 4.0 x4 controller that is that is designed for mainstream DRAM-less SSDs, and in the case of the Rocket Nano, is paired with 3D TLC memory. The SSD is available in a single 1TB configuration, and is rated for read speeds up to 5 GB/s. Interestingly, the Phison E27T controller itself is rated for read speeds up to 7 GB/s, so it appears that the petite Rocket Nano isn't making full use of the controller's performance.
Sabrent positions its Rocket Nano 2242 SSD as drives for upgrading Lenovo's Legion Go portable game console, select Lenovo ThinkPad laptops, and other M.2-2242-sized PCs that can't accomodate larger 2280 drives. Keeping in mind that most devices shipping with M.2-2242 SSDscome with pretty slow stock drives, Sabrent solution seems to be a viable product for such upgrades. All the while, Sabrent's Rocket Nano 2242 will also work in systems with a PCIe 3.0 x4 M.2 slots, so the market for these drives is pretty wide.
Sabrent's Rocket Nano 2242 SSD 1 TB (SB-2142-1TB) SSD has a recommended price of $99.99, which is more or less in line with other 1 TB drives in the same form-factor and offering comparable performance. The SSD is currently available at Amazon for $101.
Sources: Tom's Hardware, Sabrent
Micron Ships Crucial-Branded LPCAMM2 Memory Modules: 64GB of LPDDR5X For $330
Published: May 8nd 2024 6:30am on AnandTech

As LPCAMM2 adoption begins, the first retail memory modules are finally starting to hit the retail market, courtesy of Micron. The memory manufacturer has begun selling their LPDDR5X-based LPCAMM2 memory modules under their in-house Crucial brand, making them available on the latter's storefront. Timed to coincide with the release of Lenovo's ThinkPad P1 Gen 7 laptop – the first retail laptop designed to use the memory modules – this marks the de facto start of the eagerly-awaited modular LPDDR5X memory era.
Micron's Low Power Compression Attached Memory Module 2 (LPCAMM2) modules are available in capacities of 32 GB and 64 GB. These are dual-channel modules that feature a 128-bit wide interface, and are based around LPDDR5X memory running at data rates up to 7500 MT/s. This gives a single LPCAMM2 a peak bandwidth of 120 GB/s. Micron is not disclosing the latencies of its LPCAMM2 memory modules, but it says that high data transfer rates of LPDDR5X compensate for the extended timings.
Micron says that LPDDR5X memory offers significantly lower power consumption, with active power per 64-bit bus being 43-58% lower than DDR5 at the same speed, and standby power up to 80% lower. Meanwhile, similar to DDR5 modules, LPCAMM2 modules include a power management IC and voltage regulating circuitry, which provides module manufacturers additional opportunities to reduce power consumption of their products.
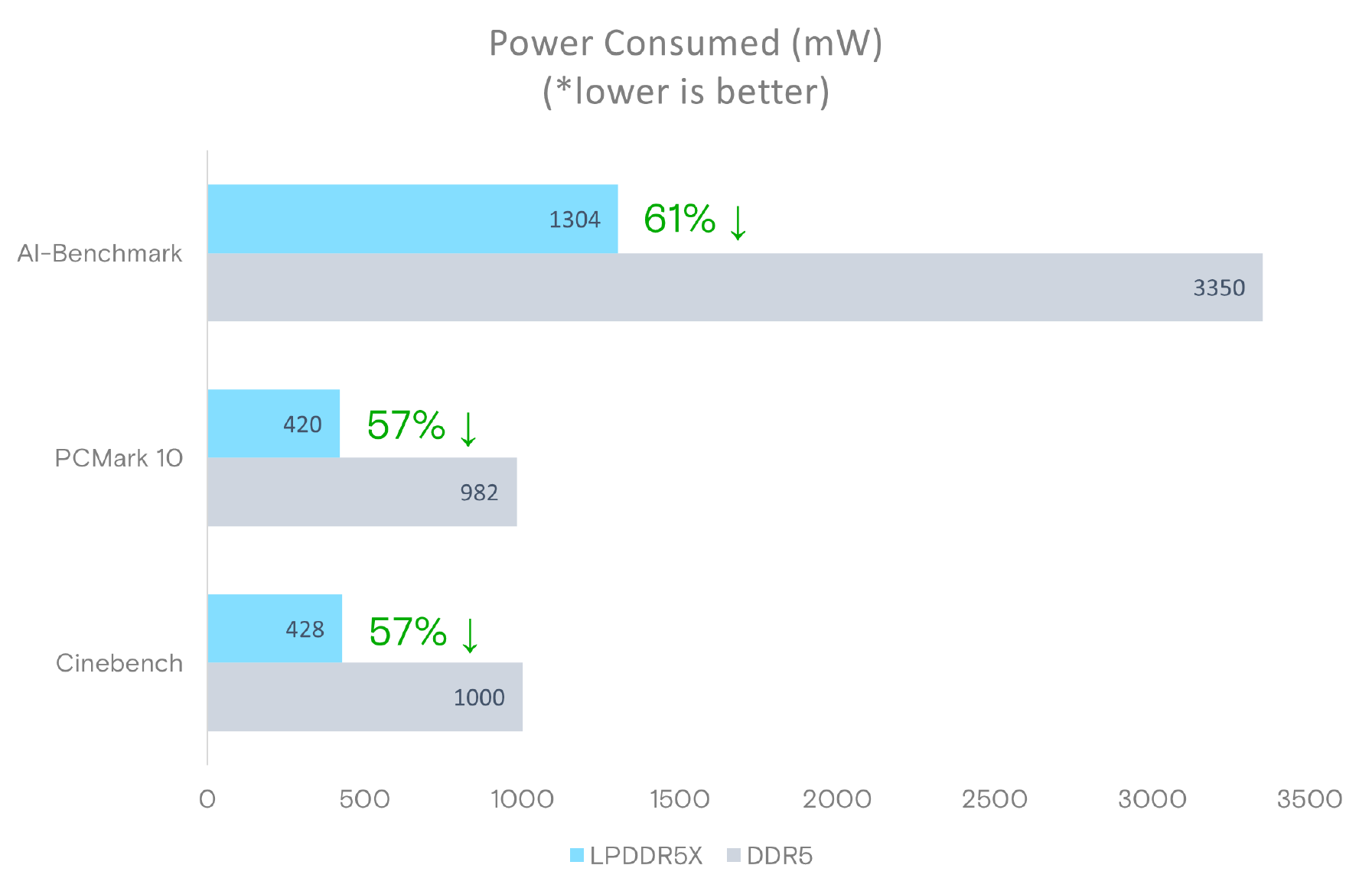 Source: Micron LPDDR5X LPCAMM2 Technical Brief
Source: Micron LPDDR5X LPCAMM2 Technical Brief
It's worth noting, however, that at least for the first generation of LPCAMM2 modules, system vendors will need to pick between modularity and performance. While soldered-down LPDDR5X memory is available at speeds up to 8533 MT/sec – and with 9600 MT/sec on the horizon – the fastest LPCAMM2 modules planned for this year by both Micron and rival Samsung will be running at 7500 MT/sec. So vendors will have to choose between the flexibility of offering modular LPDDR5X, or the higher bandwidth (and space savings) offered by soldering down their memory.
Micron, for its part, is projecting that 9600 MT/sec LPCAMM2 modules will be available by 2026. Though it's all but certain that faster memory will also be avaialble in the same timeframe.
Micron's Crucial LPDDR5X 32 GB module costs $174.99, whereas a 64 GB module costs $329.99.
Intel Issues Official Statement Regarding 14th and 13th Gen Instability, Recommends Intel Default Settings
Published: May 8nd 2024 10:05am on AnandTech

Further to our last piece which we detailed Intel's issue to motherboard vendors to follow with stock power settings for Intel's 14th and 13th Gen Core series processors, Intel has now issued a follow-up statement to this. Over the last week or so, motherboard vendors quickly released firmware updates with a new profile called 'Intel Baseline', which motherboard vendors assumed would address the instability issues.
As it turns out, Intel doesn't seem to accept this as technically, these Intel Baseline profiles are not to be confused with Intel's default specifications. This means that Intel's Baseline profiles seemingly give the impression that they are operating at default settings, hence the terminology 'baseline' used, but this still opens motherboard vendors to use their interpretations of MCE or Multi-Core Enhancement.
To clarify things for consumers, Intel has sent us the following statement:
Several motherboard manufacturers have released BIOS profiles labeled ‘Intel Baseline Profile’. However, these BIOS profiles are not the same as the 'Intel Default Settings' recommendations that Intel has recently shared with its partners regarding the instability issues reported on 13th and 14th gen K SKU processors.
These ‘Intel Baseline Profile’ BIOS settings appear to be based on power delivery guidance previously provided by Intel to manufacturers describing the various power delivery options for 13th and 14th Generation K SKU processors based on motherboard capabilities.
Intel is not recommending motherboard manufacturers to use ‘baseline’ power delivery settings on boards capable of higher values.
Intel’s recommended ‘Intel Default Settings’ are a combination of thermal and power delivery features along with a selection of possible power delivery profiles based on motherboard capabilities.
Intel recommends customers to implement the highest power delivery profile compatible with each individual motherboard design as noted in the table below:
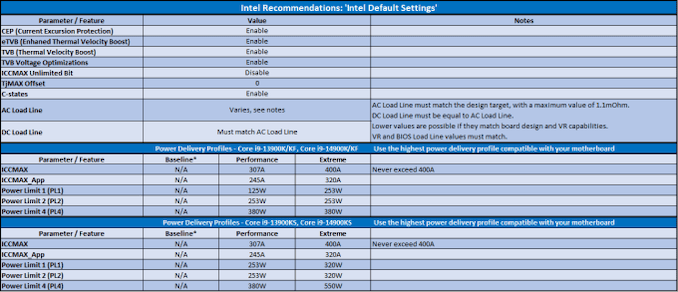 Click to Enlarge Intel's Default Settings
Click to Enlarge Intel's Default Settings
What Intel's statement is effectively saying to consumers, is that users shouldn't be using the Baseline Power Delivery profiles which are offered by motherboard vendors through a plethora of firmware updates. Instead, Intel is recommending users opt for Intel Default Settings, which follows what the specific processor is rated for by Intel out of the box to achieve the clock speeds advertised, without users having to worry about firmware 'over' optimization which can cause instability as there have been many reports of happening.
Not only this, but the Intel Default settings offer a combination of thermal specifications and power capabilities, including voltage and frequency curve settings that apply to the capability of the motherboard used, and the power delivery equipped on the motherboard. At least for the most part, Intel is recommending users with 14th and 13th-Gen Core series K, KF, and KS SKUs that they do not recommend users opt in using the Baseline profiles offered by motherboard vendors.
Digesting the contrast between the two statements, the key differential is that Intel's priority is reducing the current going through the processor, which for both the 14th and 13th Gen Core series processors is a maximum of 400 A, even when using the Extreme profile. We know those motherboard vendors on their Z790 and Z690 motherboards opt for an unrestricted power profile, which is essentially 'unlimited' power and current to maximize performance at the cost of power consumption and heat, which does exacerbate problems and can lead to frequent bouts of instability, especially on high-intensity workloads.
Another variable Intel is recommending is that the AC Load Line must match the design target of the processor, with a maximum value of 1.1 mOhm, and that the DC Load Line must be equal to the AC Load Line; not above or below this recommendation for maximum stability. Intel also recommends that CEP, eTVB, C-states, TVB, and TVB Voltage Optimizations be active on the Extreme profile to ensure stability and performance are consistent.
Given Intel is essentially recommending users not to use what motherboard vendors are offering to fix, we agree that when motherboards come out of the box, they should operate at 'Default' settings until asked otherwise. We understand that motherboard vendors have the desire to showcase what they can do with their wares, features, and firmware, but ultimately there is some real lack of communication between Intel and its partners regarding this issue.
Following Intel's statement, they do recommend customers implement the highest power delivery profile which is compatible with the caliber of motherboard used by following the specification and design. According to Intel, this isn't open for interpretation despite what motherboard vendors have offered so far, and we do expect that there is likely to be more to come in this saga of constant developments regarding the instability issue.
ASUS to Unveil First Qualcomm Snapdragon X Elite-Based Laptop On May 20th
Published: May 7nd 2024 3:30am on AnandTech

Asus on Tuesday said that it would announce its first 'AI PC' based on Qualcomm's Snapdragon X Elite system-on-chips later this month. The new laptop is set to be introduced at the Next Level. AI Incredible virtual launch event on May 20.
The launch of Asustek's new Vivobook S 15 will be hosted by Asus and will be joined by representatives of Qualcomm and Microsoft, who will reveal how they collaborated with PC maker to develop the first notebook based on Qualcomm's Snapdragon X Elite processors. These new SoCs promise to have a significant impact on the PC market in the coming quarters as they are based on the Arm instruction set architecture and are expected to bring together high performance, on-device AI acceleration, and long battery life.
Qualcomm itself calls systems powered by its Snapdragon processors as AI PCs, which is exactly how Asus calls it Vivobook S15 as well. Meanwhile, the only things we know about the machine for now is that it will be based on Qualcomm's Snapdragon X Elite or Snapdragon X Plus processors with 12 or 10 Oryon CPU cores (originally developed by Nuvia), a high-end Adreno GPU, and a 45 TOPS NPU; will come in a metallic chassis, and will feature a 15-inch display.
"The launch event, which will feature a collaboration between Microsoft, Qualcomm, and Asus, celebrates the first of the new-era Asus AI PCs, which are set to redefine the very fabric of computing," a statement by Asus reads. "The new laptop will usher in a new era of Asus AI PCs, breaking traditional boundaries and harnessing advanced AI capabilities. With comprehensive support for the latest AI functionality from Asus and Microsoft, it offers personalized AI experiences tailored to individual requirements."
Asus is also scheduled showcase its Vivobook laptops based on Qualcomm's processors at Computex in June. Actual systems will be available later this year.
Upcoming AMD Ryzen AI 9 HX 170 Processor Leaked By ASUS?
Published: May 7nd 2024 2:25am on AnandTech

In what appears to be a mistake or a jump of the gun by ASUS, they have seemingly published a list of specifications for one of its key notebooks that all but allude to the next generation of AMD's mobile processors. While we saw AMD toy with a new nomenclature for their Phoenix silicon (Ryzen 7040 series), it seems as though AMD is once again changing things around where their naming scheme for processors is concerned.
The ASUS listing, which has now since been deleted, but as of writing is still available through Google's cache, highlights a model that is already in existence, the VivoBook S 16 OLED (M5606), but is listed with an unknown AMD Ryzen AI 9 HX 170 processor. Which, based on its specificiations, is certainly not part of the current Hawk Point (Phoenix/Phoenix 2) platform.
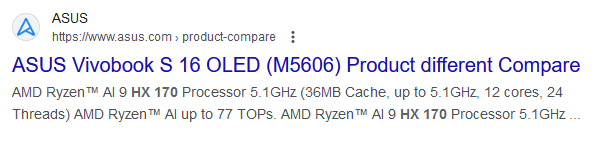 The cache on Google shows the ASUS Vivobook S 16 OLED with a Ryzen AI 9 HX 170 Processor
The cache on Google shows the ASUS Vivobook S 16 OLED with a Ryzen AI 9 HX 170 Processor
While it does happen in this industry occasionally, what looks like an accidental leak by ASUS on one of their product pages has unearthed an unknown processor from AMD. This first came to our attention via a post on Twitter by user @harukaze5719. While we don't speculate on rumors, we confirmed this ourselves by digging through Google's cache. Sure enough, as the image above from Google highlights, it lists a newly unannounced model of Ryzen mobile processor. Under the listing via the product compare section for the ASUS Vivobook S 16 OLED (M5606) notebook, it is listed with the AMD Ryzen AI 9 HX 170, which appears to be one of AMD's upcoming Zen 5-based mobile chips codenamed Strix Point.
So with the seemingly new nomenclature that AMD has gone with, it has a clear focus on AI, or rather Ryzen AI, by including it in the name. The Ryzen AI 9 HX 170 looks set to be a 12C/24T Zen 5 mobile variant, with their Ryzen AI NPU or similar integrated within the chip. Given that Microsoft has defined that only processors with an NPU with 45 TOPS of performance or over constitute being considered an 'AI PC', it's likely the Xilinx (now AMD Xilinx) based NPU will meet these requirements as the listing states the chip has up to 77 TOPS of AI performance available. The HX series is strikingly similar to AMD's (and Intel's) previous HX naming series for their desktop replacement SKUs for laptops, so assuming any of the details of ASUS's error are correct, then this is presumably a very high-end, high-TDP part.
 AMD Laptop Roadmap from Zen 2 in 2019 to Zen 5 on track for release in 2024
AMD Laptop Roadmap from Zen 2 in 2019 to Zen 5 on track for release in 2024
We've known for some time that AMD plans to release AMD's Zen 5-based Strix Point line-up sometime in 2024. Given the timing of Computex 2024, which is just over four weeks away, we still don't quite have the full picture of Zen 5's performance and its architectural shift over Zen 4. AMD CEO Dr. Lisa Su also confirmed that Zen 5 will come with enhanced RDNA graphics within the Strix Point SoC by stating "Strix combines our next-gen Zen 5 core with enhanced RDNA graphics and an updated Ryzen AI engine to significantly increase the performance, energy efficiency, and AI capabilities of PCs,"
While it's entirely possible as we lead up to Computex 2024 that AMD is prepared to announce more details about Zen 5, nothing is confirmed. We do know that the CEO of AMD, Dr. Lisa Su is scheduled to deliver the opening keynote of the show, Dr. Lisa Su unveiled their Zen 4 microarchitecture at Computex 2022 during AMD's keynote and even unveiled their 3D V-Cache stacking, which we know today as the Ryzen X3D CPUs back at Computex 2021.
With that in mind, AMD and Dr. Lisa Su love to announce new products and architectures at Computex, so we just have to wait until the beginning of next month. How AMD denotes the nomenclature for the upcoming Zen 5 mobile and desktop processors remains to be seen, but hopefully, all will be revealed soon. Regarding the ASUS Vivobook S 16 OLED (M5606), we currently don't know any of the other specifications at this time. Still, we expect them to be available once AMD has updated us with information on Zen 5 and Strix Point.
Apple Announces M4 SoC: Latest and Greatest Starts on 2024 iPad Pro
Published: May 7nd 2024 2:00am on AnandTech
Setting things up for what is certainly to be an exciting next few months in the world of CPUs and SoCs, Apple this morning has announced their next-generation M-series chip, the M4. Introduced just over six months after the M3 and the associated 2023 Apple MacBook family, the M4 is going to start its life on a very different track, launching alongside Apple’s newest iPad Pro tablets. With their newest chip, Apple is promising class-leading performance and power efficiency once again, with a particular focus on machine learning/AI performance.
The launch of the M4 comes as Apple’s compute product lines have become a bit bifurcated. On the Mac side of matters, all of the current-generation MacBooks are based on the M3 family of chips. On the other hand, the M3 never came to the iPad family – and seemingly never will. Instead, the most recent iPad Pro, launched in 2022, was an M2-based device, and the newly-launched iPad Air for the mid-range market is also using the M2. As a result, the M3 and M4 exist in their own little worlds, at least for the moment.
Given the rapid turn-around between the M3 and M4, we’ve not come out of Apple’s latest announcement expecting a ton of changes from one generation to the next. And indeed, details on the new M4 chip are somewhat limited out of the gate, especially as Apple publishes fewer details on the hardware in its iPads in general. Coupled with that is a focus on comparing like-for-like hardware – in this case, M4 iPads to M2 iPads – so information is thinner than I’d like to have. None the less, here’s the AnandTech rundown on what’s new with Apple’s latest M-series SoC.
Apple M-Series (Vanilla) SoCs SoC M4 M3 M2 CPU Performance 4-core 4-core 4-core (Avalanche) 16MB Shared L2 CPU Efficiency 6-core 4-core 4-core (Blizzard) 4MB Shared L2 GPU 10-Core Same Architecture as M3 10-Core New Architecture - Mesh Shaders & Ray Tracing 10-Core 3.6 TFLOPS Display Controller 2 Displays? 2 Displays 2 Displays Neural Engine 16-Core 38 TOPS (INT8?) 16-Core 18 TOPS 16-Core 15.8 TOPS Memory Controller LPDDR5X-7700 8x 16-bit CH 120GB/sec Total Bandwidth (Unified) LPDDR5-6400 8x 16-bit CH 100GB/sec Total Bandwidth (Unified) LPDDR5-6400 8x 16-bit CH 100GB/sec Total Bandwidth (Unified) Max Memory Capacity 24GB? 24GB 24GB Encode/ Decode 8K H.264, H.265, ProRes, ProRes RAW, AV1 (Decode) 8K H.264, H.265, ProRes, ProRes RAW, AV1 (Decode) 8K H.264, H.265, ProRes, ProRes RAW USB USB4/Thunderbolt 3 ? Ports USB4/Thunderbolt 3 2x Ports USB4/Thunderbolt 3 2x Ports Transistors 28 Billion 25 Billion 20 Billion Mfc. Process TSMC N3E TSMC N3B TSMC N5PAt a high level, the M4 features some kind of new CPU complex (more on that in a second), along with a GPU that seems to be largely lifted from the M3 – which itself was a new GPU architecture. Of particular focus by Apple is the neural engine (NPU), which is still a 16-core design, but now offers 38 TOPS of performance. And memory bandwidth has been increased by 20% as well, helping to keep the more powerful chip fed.
One of the few things we can infer with a high degree of certainty is the manufacturing process being used here. Apple’s description of a “second generation 3nm process” lines up perfectly in timing with TSMC’s second-generation 3nm process, N3E. The enhanced version of their 3nm process node is a bit of a sidegrade to the N3B process used by the M3 series of chips; N3E is not quite as dense as N3B, but according to TSMC it offers slightly better performance and power characteristics. The difference is close enough that architecture plays a much bigger role, but in the race for energy efficiency, Apple will take any edge they can get.

Apple’s position as TSMC’s launch-partner for new process nodes has been well-established over the years, and Apple appears to be the first company out the door launching chips on the N3E process. They will not be the last, however, as virtually all of TSMC’s high-performance customers are expected to adopt N3E over the next year. So Apple’s immediate chip manufacturing advantage, as usual, will only be temporary.
Apple’s early-leader status likely also plays into why we’re seeing the M4 now for iPads – a relatively low volume device at Apple – and not the MacBook lineup. At some point, TSMC’s N3E production capacity with catch up, and then-some. I won’t hazard a guess as to what Apple has planned for that lineup at that point, as I can’t really see Apple discontinuing M3 chips so quickly, but it also leaves them in an awkward spot having to sell M3 Macs when the M4 exists.

No die sizes have been quoted for the new chip (or die shots posted), but at 28 billion transistors in total, it’s only a marginally larger transistor count than the M3, indicating that Apple hasn’t thrown an excessive amount of new hardware into the chip. (ed: does anyone remember when 3B transistors was a big deal?)
M4 CPU Architecture: Now with ML AcceleratorsStarting on the CPU side of things, we’re facing something of an enigma with Apple’s M4 CPU core design. The combination of Apple’s tight-lipped nature and lack of performance comparisons to the M3 means that we haven’t been provided much information on how the CPU designs compare. So if M4 represents a watershed moment for Apple’s CPU designs – a new Monsoon/A11 – or a minor update akin to the Everest CPU cores in A17, remains to be seen. Certainly we hope for the latter, but absent further details, we’ll work with what we do know.
Apple’s brief keynote presentation on the SoC noted that both the performance and efficiency cores implement improved branch predication, and in the case of performance cores, a wider decode and execution engine. However these are the same broad claims that Apple made for the M3, so this is not on its own indicative of a new CPU architecture.
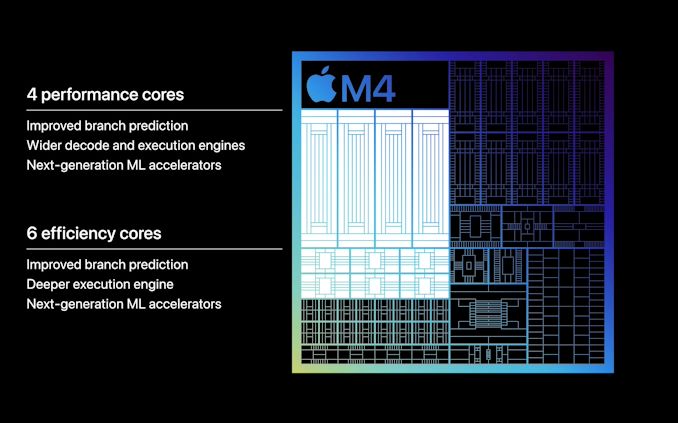
What is unique to Apple’s M4 CPU claims however are “next-generation ML accelerators” for both CPU core types. This goes hand-in-hand with Apple’s broader focus on ML/AI performance in the M4, though the company isn’t detailing on just what these accelerators entail. With the NPU to do all of the heavy lifting, the purpose of AI enhancements on the CPU cores is less about total throughput/performance and more about processing light inference workloads mixed inside more general-purpose workloads without having to spend the time and resources firing up the dedicated NPU.
A grounded guess here would be that Apple has updated their poorly-documented AMX matrix units, which have been a part of the M series of SoCs since the beginning. However recent AMX versions already support common ML number formats like FP16, BF16, and INT8, so if Apple has made changes here, it’s not something simple and straightforward such as adding (more) common formats. At the same time if it is AMX, it’s a bit surprising to see Apple mention it at all, since they are otherwise so secretive about the units.
The other reasonable alternative would be that Apple has made some changes to their SIMD units within their CPUs to add common ML number formats, as these units are more directly accessible by developers. But at the same time, Apple has been pushing developers to use higher-level frameworks to begin with (which is how AMX is accessed), so this could really go either way.
In any case, whatever the CPU cores are that underpin M4, there is one thing that is certain: there are more of them. The full M4 configuration is 4 performance cores paired with 6 efficiency cores, 2 more efficiency cores than found on the M3. Cut-down iPad models get a 3+6 configuration, while the higher-tier configurations get the full 4+6 experience – so the performance impact there will likely be tangible.
Everything else held equal, the addition of two more efficiency cores shouldn’t massively improve on CPU performance over the M3’s 4+4 configuration. But then Apple’s efficiency cores should not be underestimated, as even Apple’s efficiency cores are relatively powerful thanks to their use of out-of-order execution. Especially when fixed workloads can be held on the efficiency cores and not promoted to the performance cores, there’s a lot of room for energy efficiency gains.
Otherwise, Apple hasn’t published any detail performance graphs for the new SoC/CPU cores, so there’s little in the way of hard numbers to talk about. But the company is claiming that the M4 delivers 50% faster CPU performance than the M2. This presumably is for a multi-threaded workload that can leverage the M4’s CPU core count advantage. Alternatively, in their keynote Apple is also claiming that they can deliver M2 performance at half the power, which as a combination of process node improvements, architectural improvements, and CPU core count increases, seems like a reasonable claim.
As always, however, we’ll have to see how independent benechmarks pan out.
M4 GPU Architecture: Ray Tracing & Dynamic Caching ReturnCompared to the CPU situation on the M4, the GPU situation is much more straightforward. Having just recently introduced a new GPU architecture in the M3 – a core type that Apple doesn’t iterate on as often as the CPU – Apple has all but confirmed that the GPU in the M4 is the same architecture that was found in the M3.
With 10 GPU cores, at a high level the configuration is otherwise identical to what was found on the M3. Whether that means the various blocks and caches are truly identical to the M3 remains to be seen, but Apple isn’t making any claims about the M4’s GPU performance that could be in any way interpreted as it being superior to the M3’s GPU. Indeed, the smaller form factor of the iPad and more limited cooling capabilities means that the GPU is going to be thermally constrained under any sustained workload to begin with, especially compared to what the M3 can do in an actively-cooled device like the 14-Inch MacBook Pro.
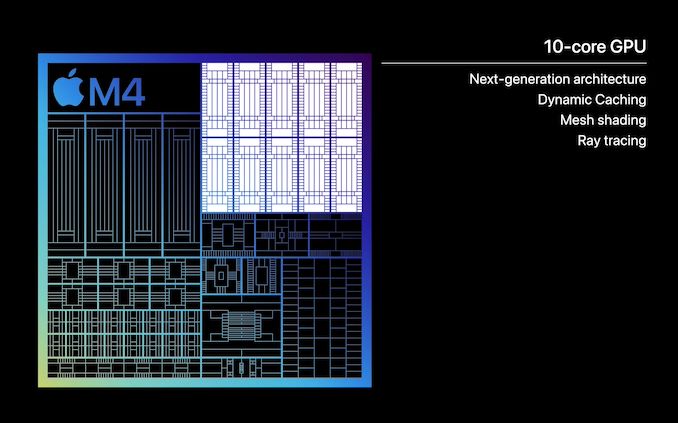
At any rate, this means the M4 comes with all of the major new architectural features introduced with the M3’s GPU: ray tracing, mesh shading, and dynamic caching. Ray tracing needs little introduction at this point, while mesh shading is a significant, next-generation means of geometry processing. Meanwhile, dynamic caching is Apple’s term for their refined memory allocation technique on M-series chips, which avoids over-allocating memory to the GPU from Apple’s otherwise unified memory pool.
GPU rendering aside, the M4 also gets the M3’s updated media engine block, which coming from the M2 is a relatively big deal for iPad uses. Most notably, the M3/M4’s media engine block added support for AV1 video decoding, the next-generation open video codec. And while Apple is more than happy to pay royalties on HEVC/H.265 to ensure it’s available within their ecosystem, the royalty-free AV1 codec is expected to take on a lot of significance and use in the coming years, leaving the iPad Pro in a better position to use the newest codec (or, at least, not have to inefficiently decode AV1 in software).
What is new to the M4 on the display side of matters, however, is a new display engine. The block responsible for compositing images and driving the attached displays on a device, Apple never gives this block a particularly large amount of attention, but when they do make updates to it, it normally comes with some immediate feature improvements.
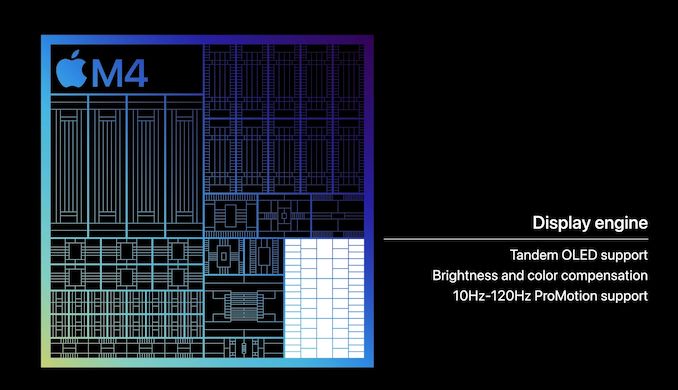
The key change here seems to be enabling Apple’s new sandwiched “tandem” OLED panel configuration, which is premiering in the iPad Pro. The iPad’s Ultra Retina XDR display places two OLED panels directly on top of each other in order allow for a display that can cumulatively hit Apple’s brightness target of 1600 nits – something that a single one of their OLED panels is apparently incapable of doing. This in turn requires a display controller that knows how to manipulate the panels, not just driving a mirrored set of displays, but accounting for the performance losses that would stem from having one panel below another.
And while not immediately relevant to the iPad Pro, it will be interesting to see if Apple used this opportunity to increase the total number of displays the M4 can drive, as vanilla M-series SoCs have normally been limited to 2 displays, much to the consternation of MacBook users. The fact that the M4 can drive the tandem OLED panels and an external 6K display on top of that is promising, but we’ll see how this translates to the Mac ecosystem if and when the M4 lands in a Mac.
M4 NPU Architecture: Something New, Something FasterArguably Apple’s biggest focus with the M4 SoC is the company’s NPU, otherwise known as their neural engine. The company has been shipping a 16-core design since the M1 (and smaller designs on the A-series chips for years before that), each generation delivering a modest increase in performance. But with the M4 generation, Apple says they are delivering a much bigger jump in performance.
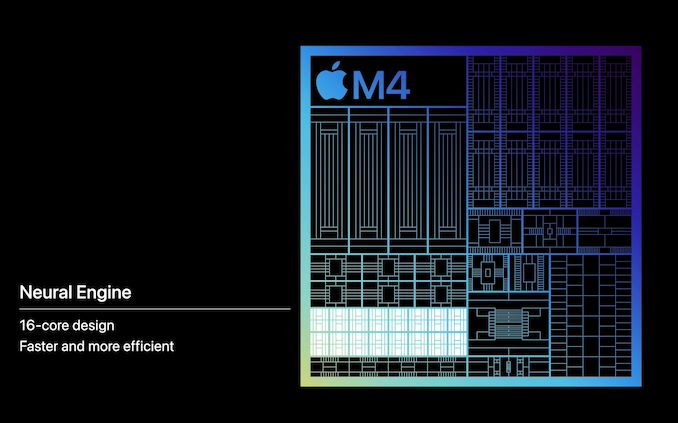
Still a 16-core design, the M4 NPU is rated for 38 TOPS, just over twice that of the 18 TOPS neural engine in the M3. And coincidentally, only a few TOPS more than the neural engine in the A17. So as a baseline claim, Apple is pitching the M4 NPU as being significantly more powerful than what’s come in the M3, never mind the M2 that powers previous iPads – or going even farther back, 60x faster than the A11’s NPU.
Unfortunately, the devil is (once again) in the details here as Apple isn’t listing the all-important precision information – whether this figure is based on INT16, INT8, or even INT4 precision. As the precision de jure for ML inference right now, INT8 is the most likely option, especially as this is what Apple quoted for the A17 last year. But freely mixing precisions, or even just not disclosing them, is headache-inducing to say the least. And it makes like-for-like specification comparisons difficult.
In any case, even if most of this performance improvement comes from INT8 support versus INT16/FP16 support, the M4 NPU is slated to deliver significant performance improvements to AI performance, similar to what’s already happened with the A17. And as Apple was one of the first chip vendors to ship a consumer SoC with what we now recognize as an NPU, the company isn’t afraid to beat its chest a bit on the matter, especially comparing it to what is going on in the PC realm. Especially as Apple’s offering is a complete hardware/software ecosystem, the company has the advantage of being able mold their software around using their own NPU, rather than waiting for the killer app to be invented for it.
M4 Memory: Adopting Faster LPDDR5XLast, but certainly not least, the M4 SoC is also getting a notable improvement in its memory capabilities. Given the memory bandwidth figures Apple is quoting for the M4 – 120GB/second – all signs point to them finally adopting LPDDR5X for their new SoC.
The mid-generation update to the LPDDR5 standard, LPDDR5X allows for higher memory clockspeeds than LPDDR5, which topped out at 6400 MT/second. While LPDDR5X is available at speeds up to 8533 MT/second right now (and faster speeds to come), based on Apple’s 120GB/second figure for the M4, this puts the memory clockspeed at roughly LPDDR5X-7700.
Since the M4 is going into an iPad first, for the moment we don’t have proper idea of its maximum memory capacity. The M3 could house up to 24GB of memory, and while it’s highly unlikely Apple has regressed here, there’s also no sign whether they’ve been able to increase it to 32GB, either. In the meantime, the iPads Pro will all either come with 8GB or 16GB of RAM, depending on the specific model.
2024 M4 iPad Pros: Coming Next WeekWrapping things up, in traditional Apple fashion, prospective tablet buyers will get the chance to see the M4 in action sooner than later. The company has already opened up pre-orders for the new iPad Pros, with the first deliveries slated to take place next week, on May 15th.

Apple is offering two sizes of the 2024 iPad Pro: 11 inches and 13 inches. Screen size aside, both sizes are getting access to the same M4 and memory configurations. 256GB/512GB models get a 3+6 core CPU configuration and 8GB of RAM, meanwhile the 1TB and 2TB models get a fully-enabled M4 SoC with a 4+6 CPU configuration and 16GB of RAM. The GPU configuration on both models is identical, with 10 GPU cores.
Pricing starts at $999 for the 256GB 11-inch model and $1299 for the 256GB 13-inch model. Meanwhile a max-configuration 13-inch model with 2TB of storage, Apple’s nano-texture matte display, and cellular capabilities will set buyers back a cool $2599.
VESA Rolls Out DisplayHDR 1.2 Spec: Adding Color Accuracy, Black Crush, & Wide-Color Gamuts For All
Published: May 7nd 2024 12:00am on AnandTech
VESA this morning is taking the wraps off of the next iteration of its DisplayHDR monitor certification standard, DisplayHDR 1.2. Designed to raise the bar on display quality, the updated DisplayHDR conformance test suite imposes new luminance, color gamut, and color accuracy requirements that extend across the entire spectrum of DisplayHDR tiers – including the entry-level DisplayHDR 400 tier. With vendors able to being certifying displays for the new standard immediately, the display technology group is aiming to address the advancements in the display technology market over the last several years, while enticing display manufacturers to make use of them to deliver better desktop and laptop displays than before.
Altogether, the DisplayHDR 1.2 is easily the biggest update to the standard since it launched in 2017, and in many respects the first significant overhaul to the standard since that time as well. DisplayHDR 1.2 doesn’t add any new tiers to the standard (e.g. 1400), instead it’s all about increasing and/or tightening the specifications at each of its tier levels. In short, the VESA is raising the bar for displays to reach DisplayHDR compliance, requiring a higher level of performance and testing for more corner cases that trip up lesser displays.
All of these changes are coming, in turn, after over half a decade of technology improvements in the display space. Whereas even the original DisplayHDR 400 requirements represented a modestly premium display in 2017, nowadays even sub-$200 displays can hit those relatively loose requirements as panels and backlighting solutions have improved. And even at the high-end of things, full array local dimming (FALD) displays have gone from hundreds of zones to thousands. All of which has finally pushed VESA’s member companies into allowing higher standards going forward.
Samsung Tapes Out Its First 3nm Smartphone SoC, Gets A Boost From Synopsys AI-Enabled Tools
Published: May 3nd 2024 4:30am on AnandTech

This week Samsung Electronics and Synopsys announced that Samsung has taped out its first mobile system-on-chip on Samsung Foundry's 3nm gate-all-around (GAA) process technology. The announcement, coming from electronic design automation Synopsys, further notes that Samsung used the Synopsys.ai EDA suite to place-n-route the layout and verify design of the SoC, which in turn enabled higher performance.
Samsung's unnamed high-performance mobile SoC relies on 'flagship' general-purpose CPU and GPU architectures as well as various IP blocks from Synopsys. SoC designers used Synopsys.ai EDA software, including the Synopsys DSO.ai to fine-tune design and maximize yields as well as Synopsys Fusion Compiler RTL-to-GDSII solution to achieve higher performance, lower power, and optimize area (PPA).
And while the news that Samsung has developed a high-performance SoC using the Synopsys.ai suite is important, there is another, even more important dimension to this announcement: this means that Samsung has finally taped out an advanced smartphone application processor on its cutting-edge 3nm GAAFET process.
Although Samsung Foundry has been producing chips on its GAA-equipped SF3E (3 nm-class, 'early' node) process for almost two years now, Samsung Electronics has never used this technology for its own system-on-chips for smartphones or other complex devices. To date, SF3E has been used mainly for cryptocurrency mining chips, presumably due to the inevitable early teething and yield issues that come with being the industry's first commercial GAAFET process.
For now, Samsung isn't disclosing what specific process node is being used for the SoC; the official Samsung/Synposys announcement only notes that it's for a GAA process node. Along with their first-generation 3nm-class SF3E, Samsung Foundry has a considerably more sophisticated SF3 manufacturing technology that offers numerous improvements over SF3E, and is due to be used for mass production in the coming quarters. Given the timing of the announcement, the reasonable bet is that they're using SF3.
As for Samsung's tooling partnership with Synopsys, the latter's tools are being credited for delivering some significant performance improvements to the chip's design. In particular, the two firms are crediting those tools for improving the chip's peak clockspeed by 300MHz while cutting down on dynamic power usage by 10%. To accomplish that, Samsung Electronics' SoC developers used design partitioning optimization, multi-source clock tree synthesis (MSCTS), and smart wire optimization to reduce signal interference, along with a simpler hierarchical approach. And by using Synopsys Fusion Compiler, they did all this while being able to skip weeks of 'manual' design work, according to the joint press release.
"Our longstanding collaboration has delivered leading-edge SoC designs," said Kijoon Hong, vice president of SLSI at Samsung Electronics. "This is a remarkable milestone to successfully achieve the highest performance, power and area on the most advanced mobile CPU cores and SoC designs in collaboration with Synopsys. Not only have we demonstrated that AI-driven solutions can help us achieve PPA targets for even the most advanced GAA process technologies, but through our partnership we have established an ultra-high-productivity design system that is consistently delivering impressive results."